It’s a human, stupid – a computational percep tion-trace model based on human interaction
Representation learning techniques are key to the deep learning revolution of the last years. For instance, in Natural Lan guage Processing (NLP), they encode the context of a word based on the surrounding words in the sentence. In computer vision, they capture visual traits from convolutions of image patches. And in network analysis, they encode the network structure of a node’s neigh borhood. Such learned representations, called embeddings, are typically represented as dense algebraic vectors and are the basis for the recent success in down-stream tasks and real-world ap plications: Even the standard keyword search by Google now uses contextual word embeddings.
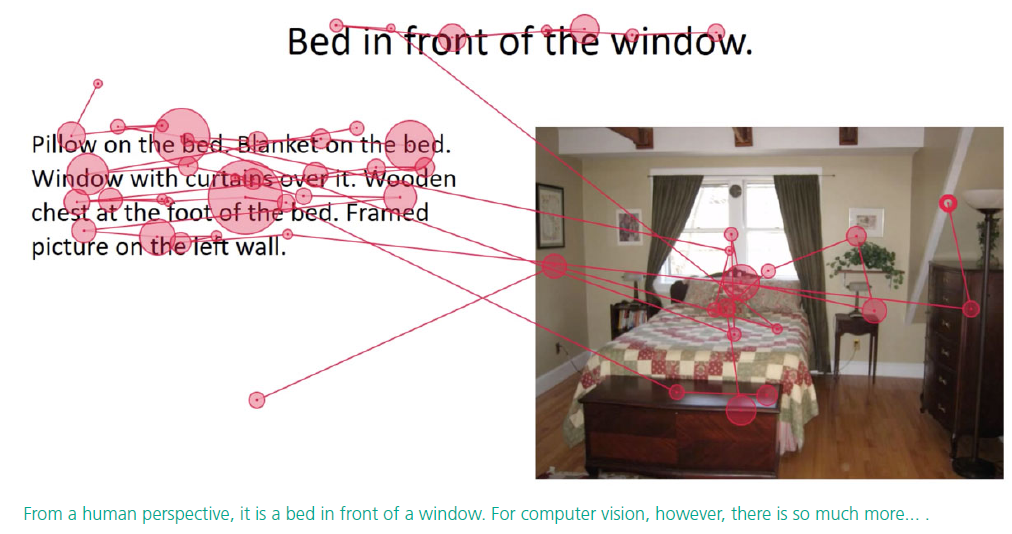
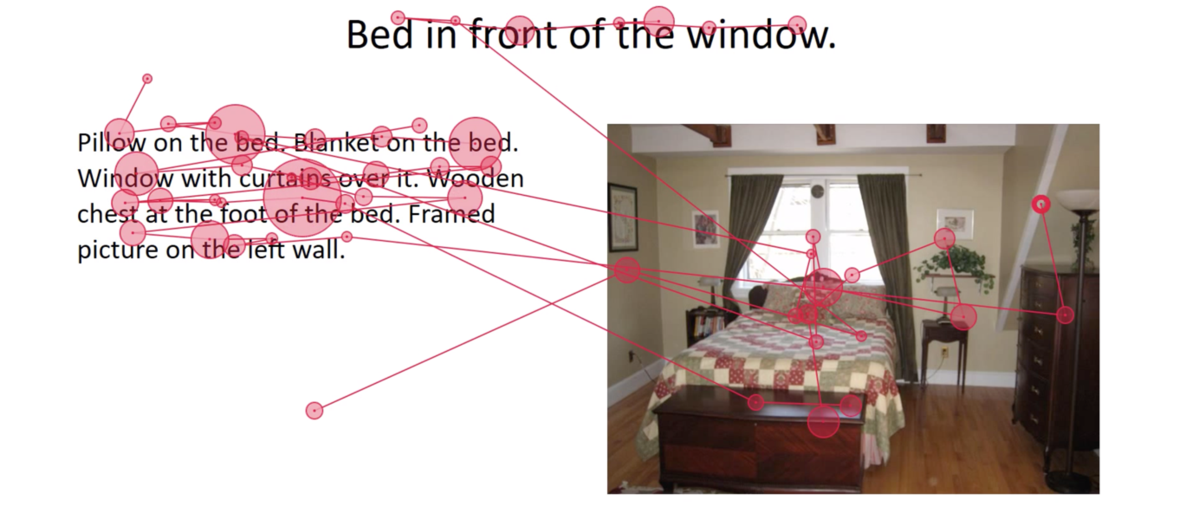
While word embeddings are trained on huge collections of documents like web pages, they attempt to extract a contextualized representa tion solely from raw text data. The hypothesis we intended to test in this project is: Multimedia documents are made by humans for humans. Thus, to better represent their content for com puters, they should be parsed in a human-like manner. For instance, when reading a multimedia webpage, (i) humans do not perceive all parts of a document equally: Some words and parts of images are skipped, others are revisited several times which makes the perception trace highly non-sequential; (ii) humans construct meaning from a document’s content by shifting their attention between text and image, among other things, guided by layout and design elements.
In this project we empirically investigated the difference between human perception and context heuristics of basic embed ding models. We conducted eye-tracking experiments to capture the underlying characteristics of human perception of media documents containing a mixture of text and images. Based on that, we de vised a prototypical computational percep tion-trace model.
We empirically evaluated how this model can improve a basic skip-gram embedding approach. Our results suggest, that even with a basic hu man-inspired computational perception model, there is a large potential for improving embed dings since such a model does inherently capture multiple modalities, as well as layout and design elements.