
A Machine Learning Approach to High- Frequency Macroeconomic Data
Economic theories often link macroeconomic and financial data. They help us understand decisions of individuals, mechanisms of how these translate into aggregate flows or resource allocation, and the consequences for wealth, prosperity, and equality in our society. Hence, they play an important role in informing policy makers. It is crucial to test these theories with high-quality data. While financial data are available at high frequencies of up to milliseconds, a problem in the field of financial economics is the low frequency of macroeconomic data. For example, aggregate consumption flows are very difficult to measure and good quality data are only available at annual frequencies. This circumstance hampers the testability of economic theories. With support of the YIN Grant, Julian Thimme follows up on the idea to combine big data and machine learning techniques to bring low-frequency macroeconomic data up to high frequencies by
"predicting" the variation during the years.
To work on this challenge, Julian Thimme – himself an expert in macro finance – has teamed up with two fellow scientists: Viktoria Klaus dedicates her doctoral studies to machine learning applications in financial economics; and Alexander Hillert, professor at the Goethe University Frankfurt, brings in his expertise in the field of textual analysis.
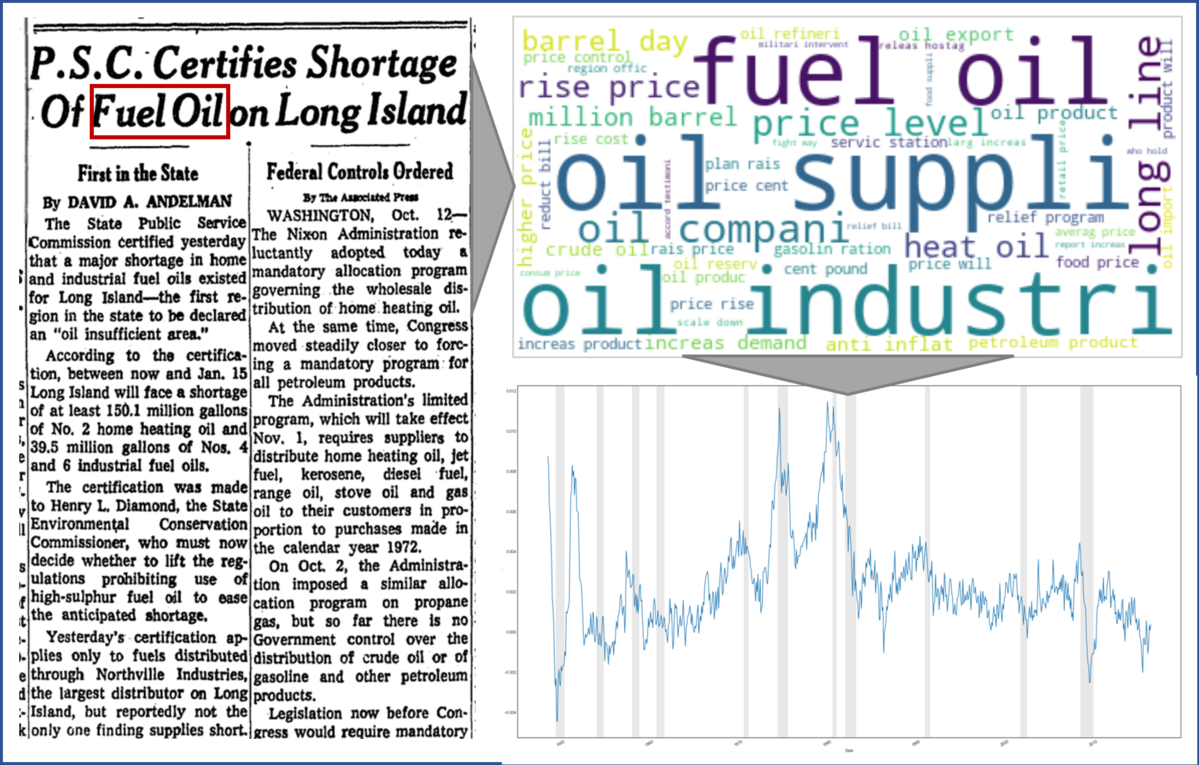
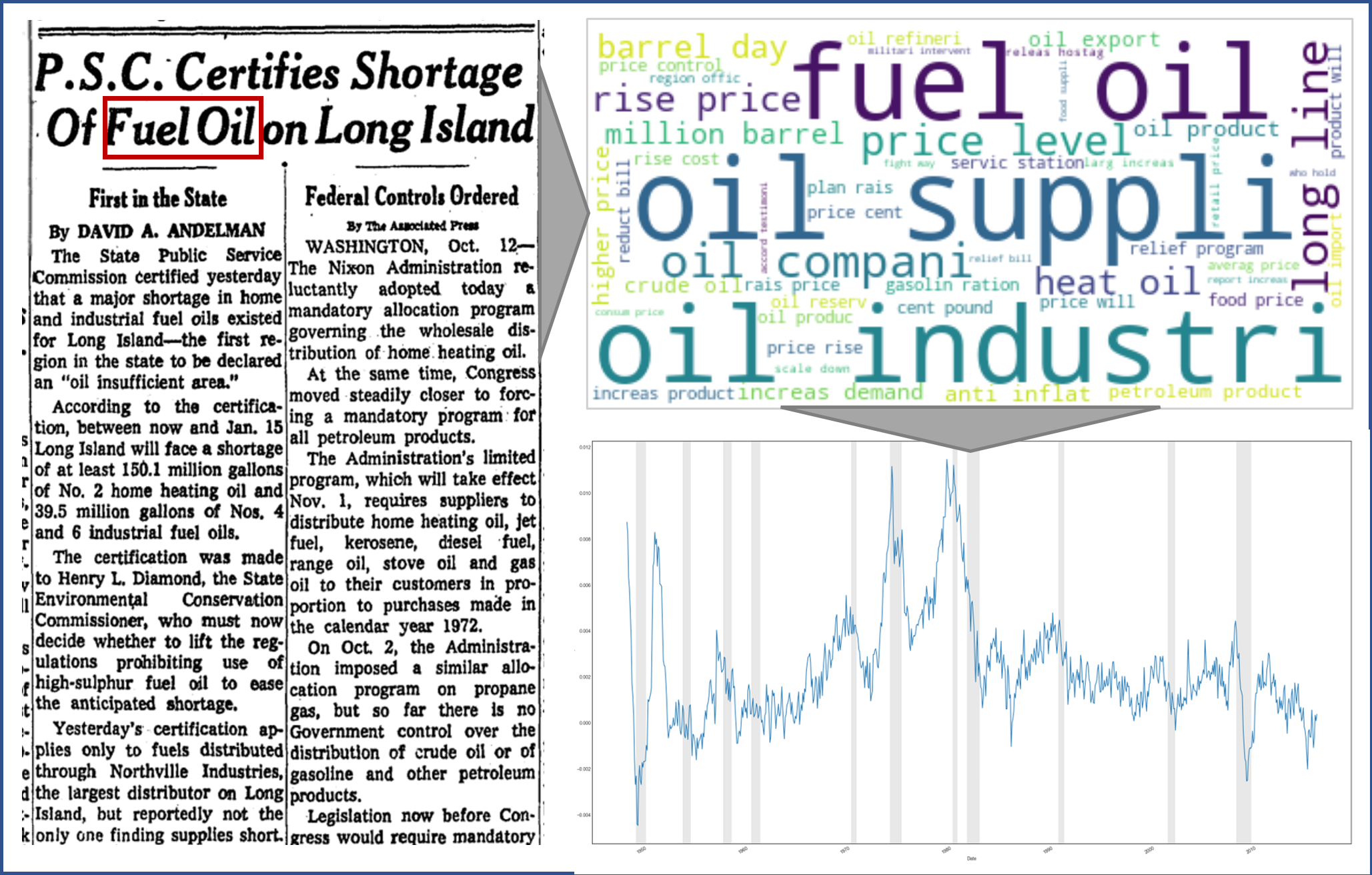
Their goal is to find predictor variables that are informative of variations in macroeconomic time series and, at the same time, available on high frequencies such as daily. These high-frequency predictors are time-aggregated to a low frequency and used in training a machine learning algorithm that selects the most important features to explain the low-frequency variations. The original high-frequency predictors can then be used to come up with a high-frequency macroeconomic time series. In addition to the technical and methodological hurdles, the approach obviously hinges upon the selection of appropriate predictor variables. Here, the team opted for a text-mining approach based on articles from a leading US newspaper. These data have been available on a daily frequency for more than a century and are likely informative about economic circumstances that have influenced the decisions of consumers and policy makers.
With the financial support of the YIN Grant, the teams installed three powerful computers that downloaded all newspaper articles of this outlet between 1923 and 2022. For more than half of the sample, only images of newspapers are available, which had to be translated into machine-readable text using optical character recognition software. With the great help of two student assistants, 12 terabytes of data were gathered, translating into a text corpus of approximately 10 billion words. This extensive data set will play an important role not only in this project (which is still work-in-progress), but also in future projects.